
Quand on dispose de données sur des dizaines ou des centaines d’organisations, une question revient naturellement : certaines se ressemblent-elles ? Peut-on les regrouper pour mieux les comprendre, et leur parler différemment ? C’est précisément l’objet du clustering.
Sommaire
Le point de départ : des scores, sept dimensions
Dans le cadre de notre étude sur la maturité data des organisations RH, chaque répondant au questionnaire a obtenu un score sur sept dimensions :
- Stratégie : la data est-elle inscrite dans la vision de l’organisation ?
- Culture : les équipes sont-elles à l’aise avec les données ?
- Architecture : les systèmes sont-ils en place pour collecter et stocker ?
- Gouvernance : qui décide quoi, avec quelles règles ?
- RGPD : les obligations réglementaires sont-elles maîtrisées ?
- Analytique : sait-on exploiter les données pour prendre des décisions ?
- Automatisation : les processus répétitifs sont-ils outillés ?
Chaque organisation se retrouve ainsi représentée par un point dans un espace à sept dimensions. L’idée du clustering est simple : trouver quels points se ressemblent, et les réunir en groupes cohérents.
L’intuition du clustering
Imaginez un nuage de points sur une feuille de papier. Certains sont proches les uns des autres, d’autres sont isolés. Naturellement, votre œil dessine des groupes. Le clustering, c’est exactement ça, mais dans sept dimensions, et avec des méthodes qui le font de façon rigoureuse et reproductible.
La difficulté, c’est que contrairement à vous avec votre feuille de papier, l’algorithme ne « voit » pas. Il calcule des distances entre points et cherche à minimiser les distances à l’intérieur des groupes, tout en maximisant les distances entre les groupes.
Étape 1 : normaliser les données
Avant de commencer, un prérequis : ramener tous les scores sur la même échelle. Si la dimension « Gouvernance » est notée sur 10 et « Automatisation » sur 100, l’algorithme serait naturellement attiré par la deuxième, qui produit des chiffres plus grands, sans que cela reflète une vraie différence d’importance.
On standardise donc chaque score pour que sa moyenne soit 0 et son écart-type soit 1. Toutes les dimensions ont désormais le même poids dans les calculs.
Étape 2 : explorer plusieurs approches
Plutôt que de se contenter d’une seule méthode, nous en avons testé quatre, chacune avec une logique différente.
K-Means est l’algorithme de clustering le plus classique. On choisit un nombre de groupes k, on place des « centres » dans l’espace, et chaque organisation est assignée au centre le plus proche. On itère jusqu’à stabilisation. Simple, rapide, interprétable.
Les Gaussian Mixture Models (GMM) apportent une nuance : plutôt qu’assigner chaque organisation à un groupe de façon tranchée, ils calculent une probabilité d’appartenance. Une organisation peut ainsi être à 72 % dans le groupe « avancé » et à 28 % dans le groupe « intermédiaire », ce qui révèle les cas en transition.
Le clustering hiérarchique construit un arbre de fusions successives : on part de chaque organisation seule, on regroupe les plus proches, et on remonte jusqu’à n’avoir plus qu’un seul ensemble. Le résultat visuel, appelé dendrogramme, permet de choisir le nombre de groupes en « coupant » l’arbre à la bonne hauteur.
Le clustering multi-niveaux pousse la logique plus loin : on sépare d’abord les organisations en deux grands groupes (maturité faible / maturité forte), puis on subdivise chacun en deux sous-groupes. On obtient ainsi quatre niveaux de maturité progressifs, du débutant à l’expert.
Étape 3 : évaluer et trancher
Comment savoir quelle approche est la meilleure ? On utilise deux métriques :
- Le score de silhouette (plus élevé = mieux) : mesure si chaque organisation est bien dans son groupe et éloignée des autres
- L’indice de Davies-Bouldin (plus bas = mieux) : mesure la compacité des groupes par rapport à leur dispersion interne
Une fois les quatre méthodes comparées sur ces critères, le verdict est clair : le K-Means obtient les meilleurs scores. Malgré sa simplicité apparente, il produit les groupes les mieux séparés et les plus cohérents sur nos données. Les approches plus sophistiquées n’apportent pas de gain statistique significatif et introduisent une complexité d’interprétation sans contrepartie.
Ces tests nous ont également permis de définir le bon nombre de clusters en évaluant dynamiquement la performance des modèles sur un nombre de clusters en 2 et 10.
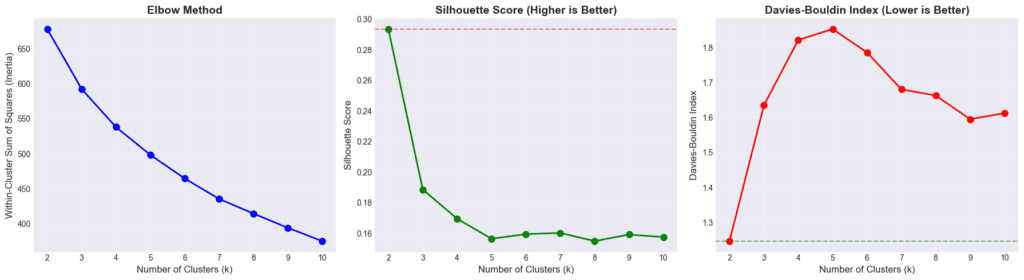
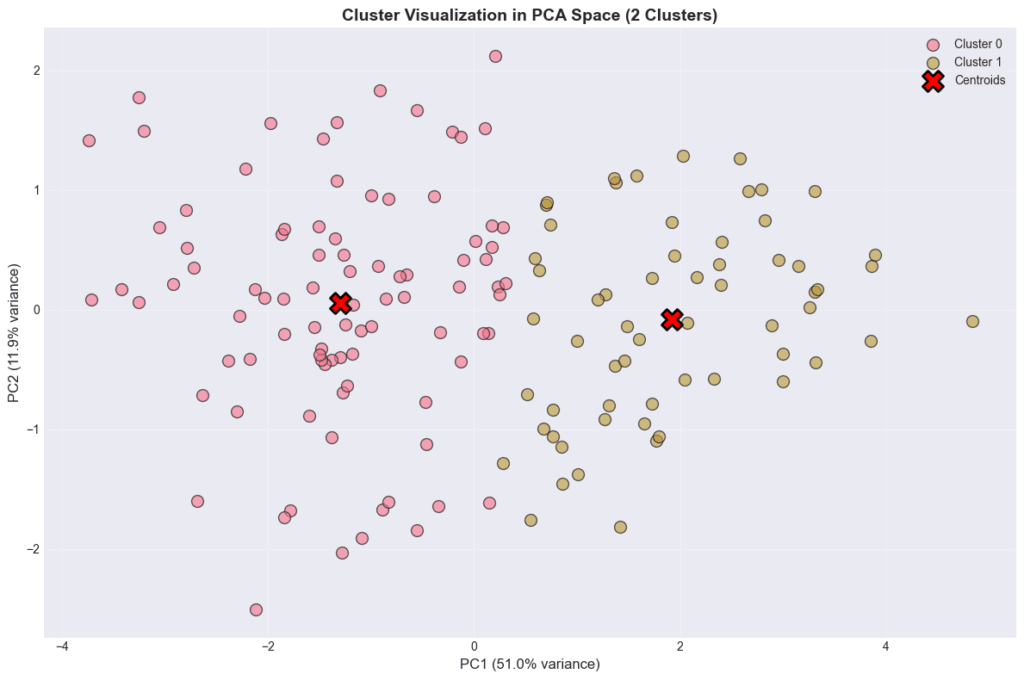
C’est un résultat courant en data science : la méthode la plus simple est souvent la plus robuste, surtout quand les données ont une structure claire. Ici, les organisations se répartissent naturellement en deux profils distincts, et le K-Means le capte très bien.
Ce qu’on en fait
Avec deux groupes bien identifiés, on peut caractériser chacun d’eux sur les sept dimensions et construire des recommandations adaptées. Les organisations du premier groupe présentent des scores homogènes et modestes sur la plupart des axes : leur priorité est de poser les fondations (gouvernance, architecture, culture data). Celles du second groupe ont déjà franchi ce cap et peuvent se concentrer sur l’exploitation avancée : analytique, automatisation, alignement stratégique.
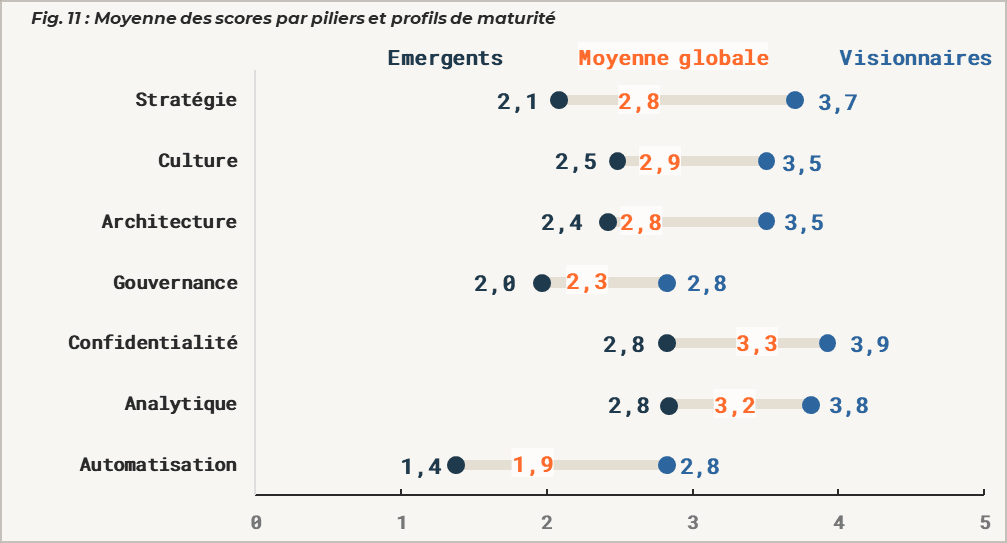
Le clustering ne dit pas quoi faire. Mais il permet de ne pas traiter tout le monde de la même façon, et c’est déjà beaucoup.
Ce que le clustering ne fait pas
Un point d’honnêteté : le clustering ne découvre pas une vérité cachée dans les données. Il impose une structure, il choisit parmi plusieurs façons de découper le nuage de points. C’est le chercheur qui décide combien de groupes sont pertinents, quelle métrique optimiser, comment interpréter les profils.
Le clustering est un outil d’exploration, pas d’explication. Il dit « ces organisations se ressemblent », pas « pourquoi elles se ressemblent » ni « que faire pour qu’elles évoluent ». C’est l’étape d’après, humaine et qualitative, qui donne du sens aux groupes produits par les algorithmes.
L’analyse présentée ici a été réalisée sur les réponses au questionnaire de maturité data RH, couvrant sept dimensions clés. Quatre méthodes de clustering (K-Means, GMM, clustering hiérarchique et multi-niveaux) ont été comparées sur des critères statistiques rigoureux. Le K-Means s’est imposé comme la méthode la plus performante sur ce jeu de données.
Retour de ping : L'importance de la Data dans les RH ? Méthode d'analyse - My People Analytics