
Cet article fait partie de la série « Un projet Data Science de bout en bout ». J’y présente les travaux réalisés dans le cadre de la formation Big Data pour l’entreprise numérique proposée par Centrale Supelec Exced. Ces travaux ont pour objectif d’identifier le métier dominant à partir d’offres d’emploi « Ressources humaines ».
Pour des questions de lisibilité, le code n’est pas intégré dans l’article. Vous pouvez le consulter en cliquant ici.
Dans l’article précédent, nous avons découvert comment nettoyer des données textuelles. Ce travail offre une première capacité de résultats. Par exemple, il est possible de compter le nombre d’occurrence des mots les plus importants, et de dresser un nuage de mots.
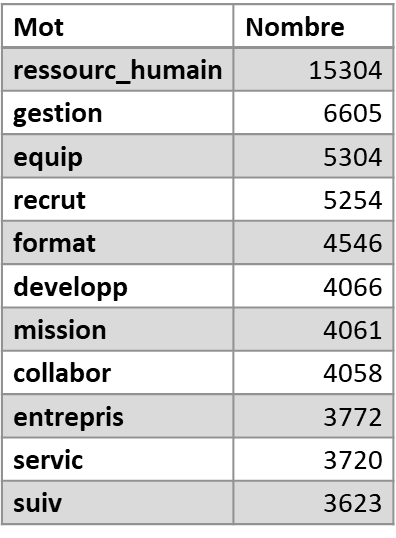
Ces résultats sont néanmoins assez basiques. Nous pouvons aller beaucoup plus loin.
Voyons comment nous avons demandé à la machine d’identifier le métier dominant de chacun de nos 3 000 offres d’emploi « Ressources Humaines » récoltées sur linkedIn.
Le topic modeling
Le topic modeling est une des opérations de Traitement du Langage Naturel les plus connues. C’est une technique d’apprentissage non supervisé permettant d’extraire les sujets principaux d’un corpus de texte. Identifier les métiers dominants dans les offres d’emploi « Ressources Humaines » est un cas d’usage particulièrement adapté.
Cette grande famille est composée de nombreux algorithmes : bag of words, Latent Semantic Analysis… Nous avons décidé d’utiliser le Latent Dirichlet Allocation. Ce choix s’explique par la versalité de l’algorithme et la puissance de ses résultats dans le package gensim que nous avons utilisé.
Principe de fonctionnement du LDA
Le Latent Dirichlet Allocation est un algorithme permettant d’identifier les mots clés composant un topic, et de rattacher les documents à chaque topic. Voici un visuel présentant schématiquement son fonctionnement :
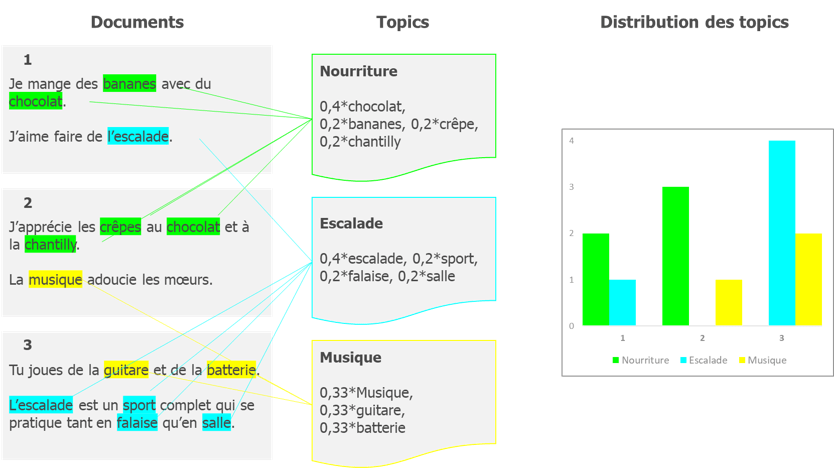
Cliquez sur ce lien lire l’article présentant le fonctionnement détaillé de l’algorithme.
Paramétrage du LDA
Nombre de topics
Comme pour un clustering, le nombre de topics est le paramètre le plan important de l’algorithme.
Mais comment le définir ?
Le nombre de topics est le croisement de la connaissance métier et technique. L’approche métier permet de connaitre grossièrement le nombre de topics. Et l’aspects technique permet, en étudiant la performance du modèle, d’affiner l’objectif. C’est ce que nous avons fait dans le cadre de nos travaux.
Nous avons décidé que le nombre de topics serait entre 1 et 19, puis nous avons exécuté l’algorithme pour chacun de ses nombres et avons calculé trois métriques de performance et les avons représenté graphiquement :
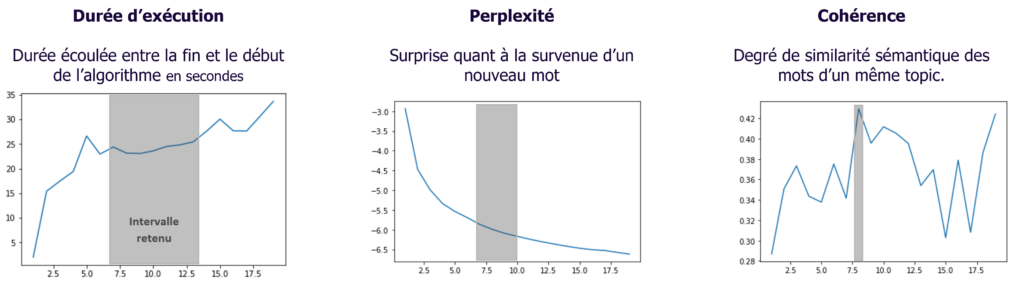
A l’appui de ces 3 métriques de performance, nous avons déduit que le nombre de topics à choisir est 8.
Les autres paramètres
Il existe d’autres paramètres, plus techniques, qui permettent de configurer le fonctionnement de l’algorithme. Nous allons présenter rapidement les 5 paramètres que nous avons personnalisé :
Les paramètres liés à l’exécution de l’algorithme
–Chunksize : Taille des vague de jeux de données transmis, nous l’avons fixé à 1000
–Passes : Nombre d’occurrences de l’algorithme, nous l’avons fixé à 10
Les paramètres liés à la finesse de l’algorithme
–Below_limit : Seuill d’occurrence des mots. Un mot qui apparait moins que le seuil ne sera pas cosidéré comme significatif. Nous l’avons d’après la taille de notre corpus : nombre de documents / 2 * nombre de topics
–Alpha : Distribution à priori des topics pour chaque document. Un alpha important attibuera des topics de façon « adoucie » En l’absence d’indice, nous l’avons mis en auto
–Eta : Distribution des mots pour chaque topic. Un Eta important tiendra compte de mots considérés comme moins discrimants par l’algorithme. Nous l’avons également fixé d’après la taille de notre corpus : nombre de mots du corpus / 10
Résultats du LDA
La puissance du LDA de gensim réside dans sa capacité rapide à produire des résultats exploitables.
Ainsi, il est possible de produire une visualisation intéractive de l’analyse.
A gauche, on retrouve une représentation des clusters sur un axe orthonormé d’après composantes principales de notre modèle.
A droite, on retrouve les termes les plus importants de notre modèle. La visualisation permet de sélectionner un topic ce qui filtre les termes les plus importants pour représenter notre modèle. Il est également possible de survoler un mot pour identifier les topics concernés par celui-ci.
Est-ce que vous arrivez à retrouver les principaux métiers RH dans chacune des bulles ?
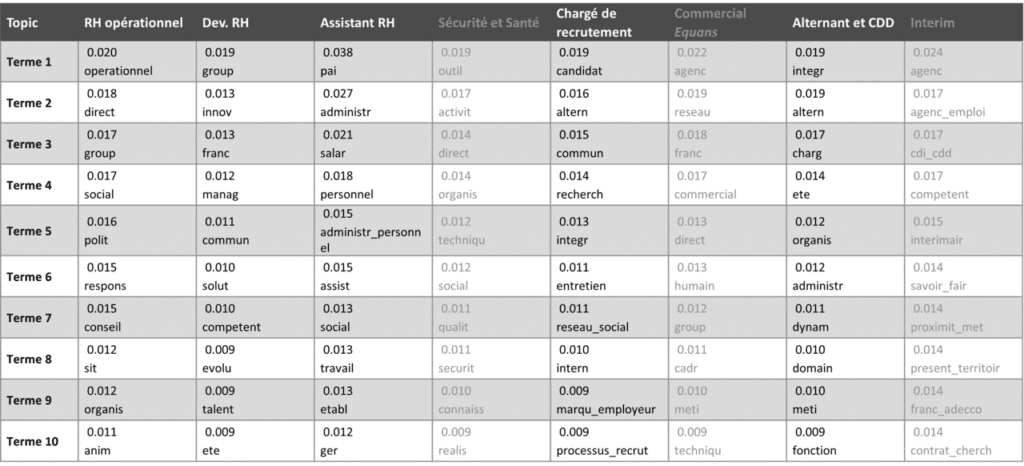
C’est ce travail que j’ai réalisé afin d’associer chaque topic avec un métier RH. On retrouve dans le tableau les 10 mots les plus importants pour chaque topics ainsi que leur poid dans ce topic.
Il est également possible d’exporter les résultats afin de les analyser :
Dominant topic : une base contenant, pour chaque document, le topic dominant.
Mixture : le détail, pour chaque documents, de la part de topics associés.
Interprétation des résultats
Il devient dès lors possible de produire plusieurs types de visualisations pour comprendre les phénomènes que nous avons analysé.
Comparaison entre %Somme et %Nombre
Notre interprétation des topics se base sur les offres d’emploi les plus représentatives de chaque topic, c’est-à-dire à partir de 90% dans la table mixture. En réalité, il est possible, pour chaque offre d’emploi, d’identifier des hybridations. Par exemple, nous retrouvons des alternants en charge de la gestion administrative. Il est possible d’avoir une vue de l’hybridation en distinguant la part du total pour la somme des mixtures et le nombre de mixture pour chaque topic.
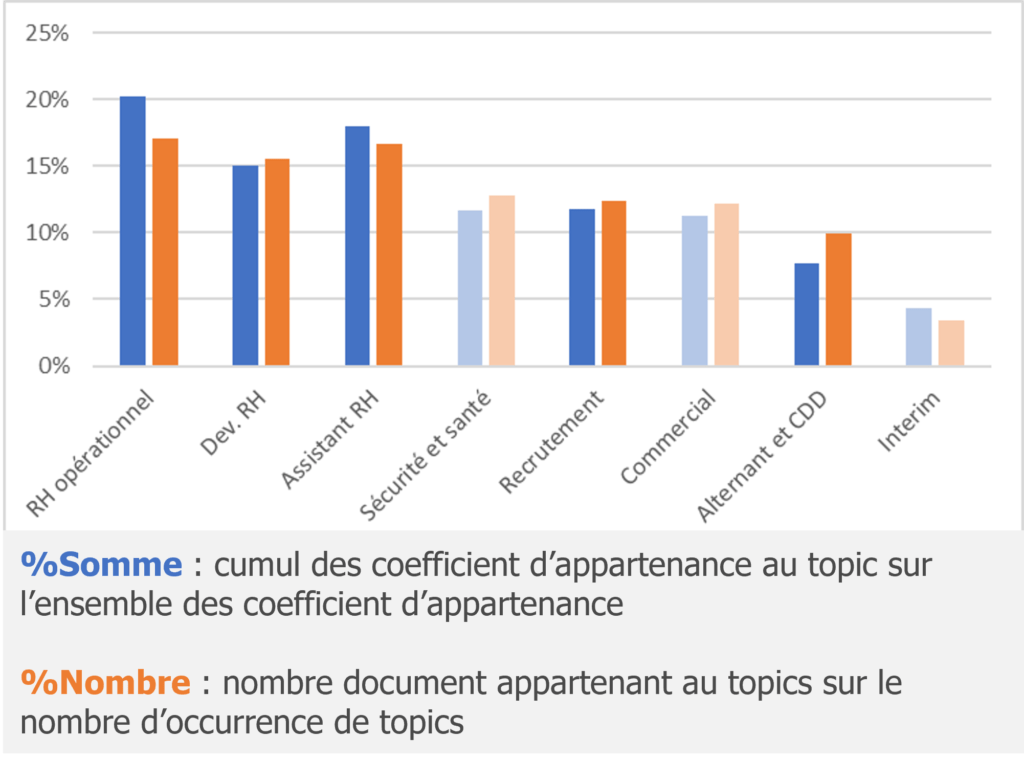
On se rend compte que le topic 1, RH généraliste, présente une somme bien plus importante que son nombre. Cela signifie que relativement peu d’offre d’emploi sont rattachés à ce topic mais que leur poids est plus important. Au contraire, le topic 5, recruteur, est plus diffus dans les autres topics. Ce qui est d’ailleurs confirmé par la table de corrélation (voir figure 12).
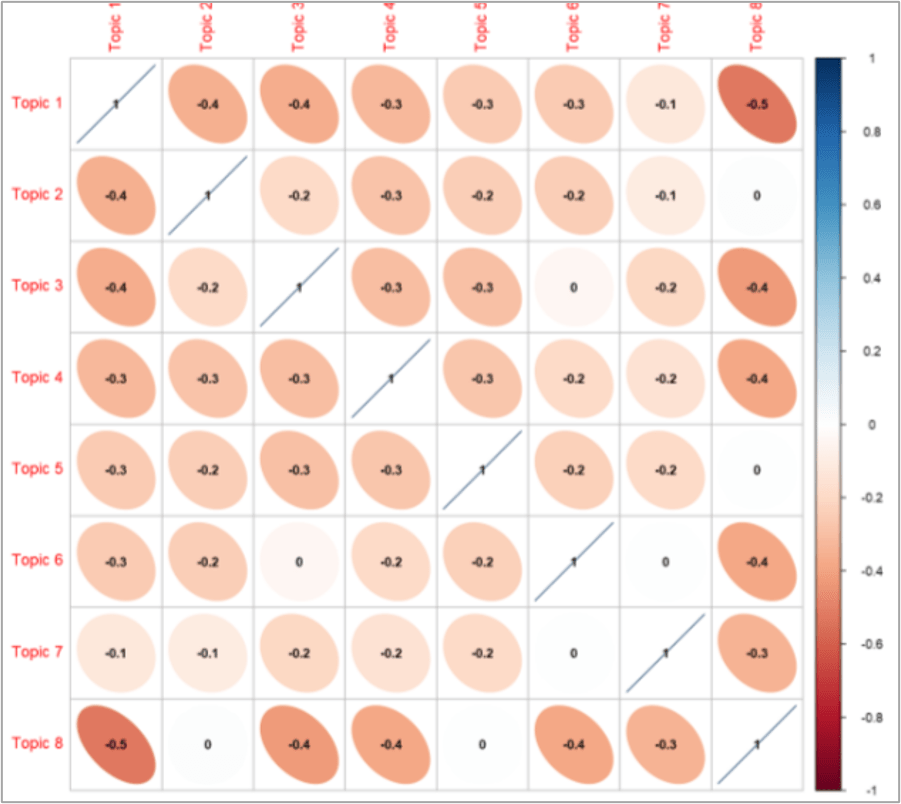
Lien entre les différents topics
Afin de mieux comprendre les liens qui existent entre les données, nous pouvons constituer une matrice de corrélation à partir de la table Mixture. On constate que les topics présentent de corrélation négatives. Cela veut dire que la présence d’un topic diminue la présence des autres. Les Mixtures sont en effet la part de chaque topic contenue dans chaque document. Ainsi, plus un topic est présent, moins il laisse de place aux autres. On peut cependant mettre en évidence que le topic 8, le moins important du corpus, présente les corrélations les plus discriminantes. Ceci veut dire que sa présence fait « disparaître » rapidement les topics 1, 3, 4 et 6.
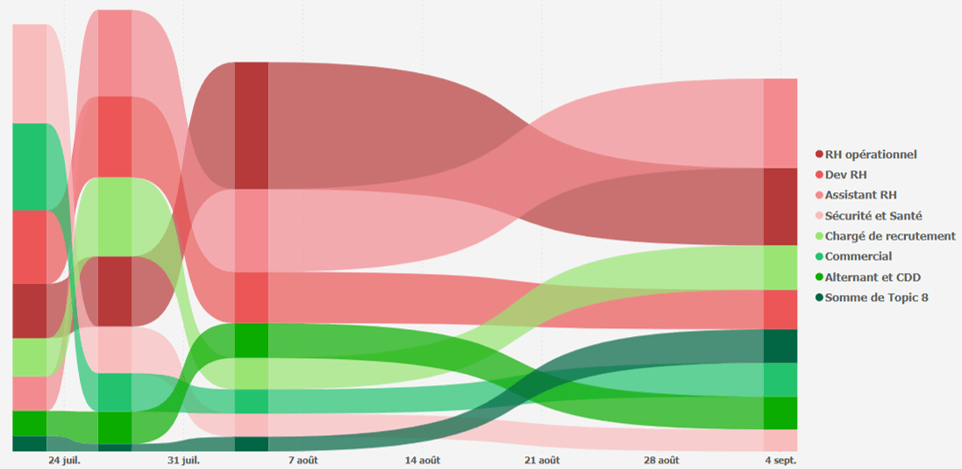
Evolution temporelle
Enfin, étant donné que nous avons réalisé plusieurs extractions, il est possible de réaliser une analyse temporelle de l’évolution des métiers. Avec plus de recul, nous pourrions chercher de la saisonalité dans les besoins d’offres d’emploi.
En conclusion
Nous avons vu dans cette série d’article comment nous pouvons récolter, préparer et analyser des corpus de texte.
Nous avons décidé de faire cet exercice pour les offres d’emploi « Ressources Humaines ». Mais les possibilités sont infinies : CV / lettres de motivations, entretiens annuels, fiches de postes… Les RH utilisent le langage au quotidien pour représenter la complexité de leur fonction.
Et vous, comment allez-vous utiliser le texte ?